Entrar
Construa seu site
Escala de Banco de Dados: Estratégias e Melhores Práticas (Atualizado em 2025)
Para gerar mais tráfego e melhorar o fluxo de dados, compilamos estratégias e melhores práticas para ajudar você a otimizar a escala do banco de dados. Experimente agora.

Sua empresa está tendo dificuldade para acompanhar as demandas crescentes e gerenciar efetivamente os dados e usuários em aumento? Pode ser hora de escalar seu banco de dados. Neste artigo, você descobrirá passos práticos para otimizar seu sistema sobrecarregado e prepará-lo para o crescimento futuro.

O que é Escalabilidade de Banco de Dados
Um banco de dados é uma coleção organizada de dados, frequentemente referida como dados estruturados, que podem ser armazenados e acessados em um sistema de computador. Bancos de dados são especificamente projetados para gerenciar, armazenar e recuperar informações de forma eficiente. Um Sistema de Gerenciamento de Banco de Dados (DBMS) geralmente controla um banco de dados. Ele simplifica o acesso, gerenciamento e atualização dos dados no banco de dados.
Escalabilidade de banco de dados significa ajustar o tamanho e a capacidade de um banco de dados. Isso é feito para atender às demandas crescentes, como mais dados e usuários. Ela deve manter o desempenho, a responsividade e a confiabilidade. Construir um banco de dados escalável garante uma experiência do usuário sem problemas, mesmo que o sistema aumente.
Escalabilidade de Banco de Dados: Estratégias e Boas Práticas (Atualizado 2025)
Pronto para otimizar seu banco de dados para crescimento e desempenho? Compilei estratégias e boas práticas essenciais para ajudá-lo a escalar seu banco de dados de forma eficaz.
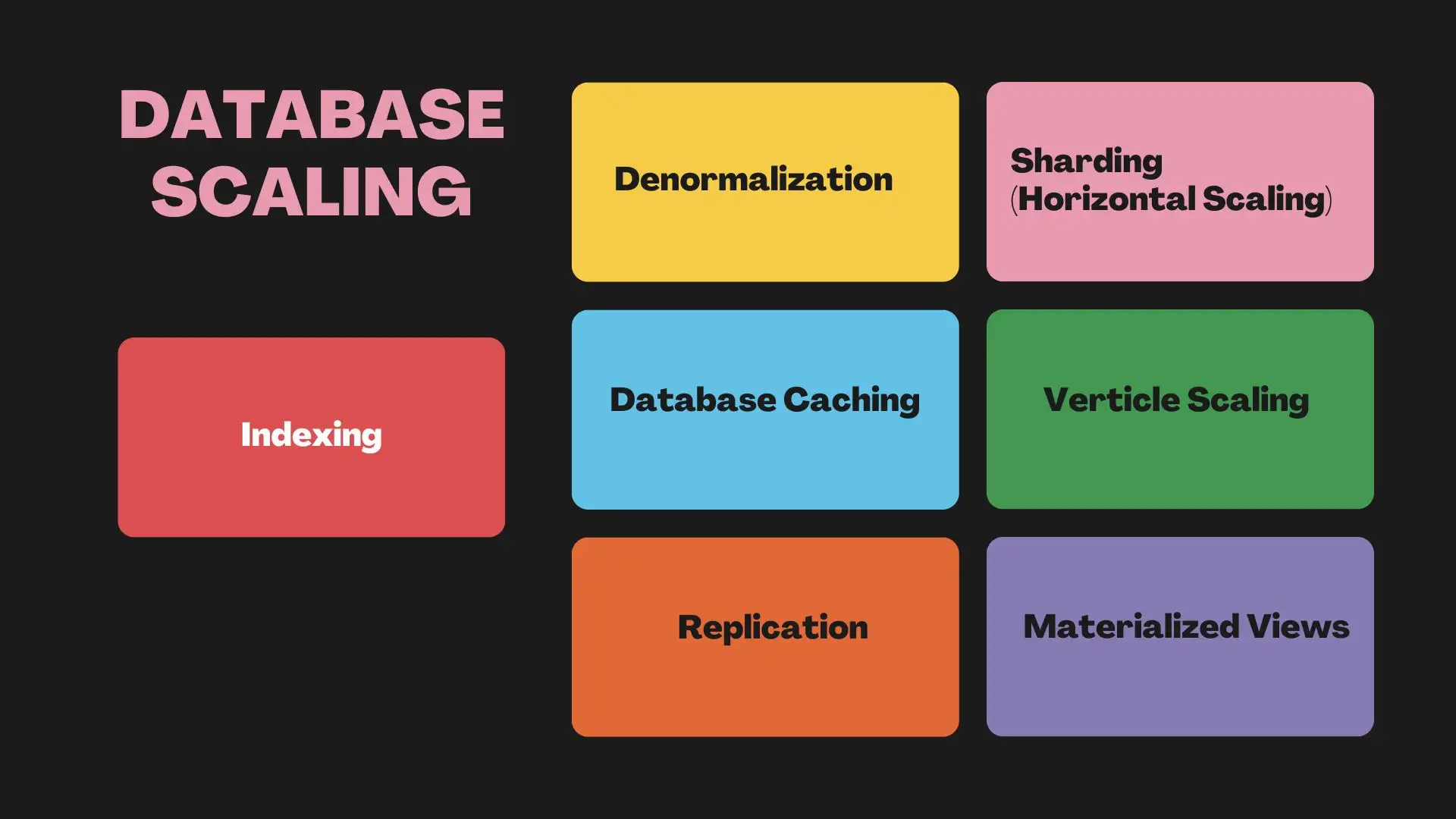
1#Indexação
A indexação de banco de dados é essencial para a escalabilidade do banco de dados. Ela acelera a recuperação de dados permitindo buscas mais rápidas. É como um índice de livro, que ajuda a encontrar tópicos sem passar por todas as páginas. Embora os índices melhorem a eficiência das pesquisas, eles exigem armazenamento adicional e operações de gravação para manter.
Práticas-chave incluem analisar e otimizar regularmente as consultas, usar pools de conexões para gerenciamento eficiente, particionar tabelas grandes e selecionar o tipo certo de banco de dados (SQL vs. NoSQL). Considere o tamanho do índice, velocidade de pesquisa, manutenção e tolerância a falhas ao projetar índices. Juntos, esses fatores ajudam a melhorar a eficiência e o desempenho geral do banco de dados.
2#Denormalização
A denormalização é uma das tcnicas de escalabilidade de banco de dados para otimização. Ela melhora o desempenho de leitura adicionando dados redundantes a um esquema anteriormente normalizado. Ela ajuda a reduzir o custo de acesso que pode aumentar devido a várias junções de tabelas em um banco de dados normalizado, especialmente ao lidar com tabelas grandes e índices.
A denormalização acelera as consultas por adicionar redundância pré-computada. No entanto, ela aumenta o armazenamento e pode causar inconsistências nos dados. Técnicas comuns incluem divisão de tabelas e adição de colunas derivadas ou redundantes. O uso de tabelas espelhadas também é comum. Não confunda esse processo com um banco de dados que nunca foi normalizado. A denormalização geralmente é feita após o esquema ter sido otimizado por meio da normalização.
Vantagens da Denormalização
-
Maior Escalabilidade: A denormalização pode tornar os sistemas de banco de dados mais escaláveis. Isso é feito reduzindo o número de tabelas e melhorando o desempenho. A denormalização reduz o número de transações do banco de dados ao ler dados. Esse número reduzido de transações pode se adaptar a diferentes cargas de usuários, melhorando assim a escalabilidade da aplicação.
-
Menor Complexidade: A denormalização pode simplificar o esquema do banco de dados. Isso é feito reduzindo consultas de junção e combinando dados relacionados em menos tabelas. Um esquema mais simples é mais fácil de entender, consultar e gerenciar. Além disso, essa simplicidade ajudará significativamente a reduzir erros relacionados às operações do banco de dados.
-
Melhor Desempenho de Consulta: A denormalização aumenta a velocidade das consultas reduzindo as junções. Dependendo das necessidades, consultar um armazenamento de dados normalizado pode exigir várias junções de diferentes tabelas.
Desvantagens da Denormalização:
-
Integridade de Dados Reduzida: A denormalização introduz dados redundantes. Isso aumenta o risco de inconsistências. Atualizações podem não se propagar corretamente em todos os campos redundantes.
-
Maior Complexidade: A denormalização pode simplificar algumas consultas. Mas também pode complicar o banco de dados criando dados duplicados. Isso pode levar a discrepâncias entre os conjuntos de dados, especialmente em cenários envolvendo bancos de dados espelhados.
-
Necessidade de Armazenamento e Custos Maiores: A denormalização cria dados redundantes. Técnicas como duplicação de dados e espelhamento de tabelas ocupam espaço. Isso aumenta os custos de armazenamento, que podem ser altos para grandes conjuntos de dados.
-
Mais Atualizações e Menor Flexibilidade: Com dados redundantes, a frequência de atualizações aumenta, complicando a manutenção do banco de dados. Isso, por sua vez, limita a flexibilidade do sistema, tornando mais difícil adaptar-se a requisitos ou modificações em mudança.
3#Cache de Banco de Dados
O cache de banco de dados também é uma das técnicas para escalar o banco de dados. Ele armazena dados frequentemente acessados na memória. Isso reduz a necessidade de consultas e cálculos repetidos no banco de dados. Este método melhora a escalabilidade e o desempenho do aplicativo. Ele reduz o tempo gasto para recuperar dados de armazenamento persistente, como discos rígidos ou SSDs.

Vantagens do Cache de Banco de Dados
-
Redução da Carga no Banco de Dados: O cache transfere consultas frequentes do banco de dados. Isso reduz a pressão sobre os recursos do servidor. Permite que o banco de dados atenda a mais solicitações de forma eficiente.
-
Melhoria no Desempenho: O cache armazena dados acessados com frequência na memória. Isso reduz drasticamente os tempos de resposta e acelera a recuperação de dados.
-
Latência Reduzida: Os dados em cache estão em estruturas rápidas de memória. Isso minimiza a latência e acelera os tempos de resposta para usuários e aplicativos.
-
Menos Operações de I/O no Disco: O cache reduz leituras no disco. Isso acelera o acesso aos dados e é mais eficiente do que o armazenamento baseado em disco.
Desvantagens do Cache de Banco de Dados
-
Invalidação do Cache: É difícil saber quando atualizar os dados em cache. No entanto, é crítico para a consistência dos dados.
-
Custo Mais Alto para Cache Externo: O cache externo frequentemente requer DRAM. É mais caro do que usar SSDs ou HDDs para armazenamento.
-
Menor Disponibilidade: Os caches externos geralmente têm menor alta disponibilidade (HA) do que os bancos de dados. Isso pode causar falhas e sobrecarregar o banco de dados durante falhas no cache.
-
Interferência com o Cache do Banco de Dados: Um cache externo pode interferir no cache interno do banco de dados. Isso torna-o menos eficaz e aumenta o acesso ao disco.
4#Replicação
Agora, vou apresentar outra técnica para escalar o banco de dados: replicação. A replicação de banco de dados copia o banco de dados e o armazena em diversos locais locais ou em nuvem. Isso garante acessibilidade dos dados, tolerância a falhas e confiabilidade. Permite que os usuários acessem os mesmos dados atualizados, melhorando o desempenho do sistema e a recuperação de desastres. A replicação geralmente ocorre em tempo real, à medida que os dados são criados, atualizados ou excluídos, mas também pode ser feita como um processo único ou em lotes agendados.

Vantagens da Replicação
-
Melhoria na Recuperação de Desastres: A replicação de dados cria cópias do banco de dados em vários locais. Isso garante alta disponibilidade e acesso durante interrupções causadas por desastres.
-
Redução da Carga nos Servidores: A replicação transfere dados para um ambiente replicado. Isso reduz a carga no banco de dados principal. Isso otimiza o desempenho e libera recursos.
-
Melhoria na Análise de Dados: A replicação cria ambientes isolados para executar consultas complexas. Isso permite que analistas explorem dados sem afetar os sistemas principais.
-
Inteligência Empresarial em Tempo Real: A replicação permite acesso a dados em tempo real em unidades empresariais. Isso melhora a precisão dos relatórios e a tomada de decisões. Também integra dados de várias fontes para uma melhor inteligência empresarial.
-
Suporte para Aplicações de IA/ML: Bancos de dados replicados fornecem conjuntos de dados consistentes e atualizados para treinar modelos de IA/ML. Isso melhora a precisão preditiva e permite aplicações em tempo real baseadas em dados.
Desvantagens da Replicação de Dados
-
Risco de Comprometimento de Dados: Erros na replicação podem corromper ou perder dados. Isso representa um risco significativo à integridade dos dados.
-
Custos Aumentados: A replicação de dados exige armazenar e transferir múltiplas cópias de dados. Isso exige muito armazenamento e largura de banda. Isso resulta em custos maiores de armazenamento e operação, incluindo a necessidade de pessoal adicional para monitorar e gerenciar o processo.
-
Riscos de Segurança de Dados: A replicação de dados, especialmente para servidores remotos, introduz vulnerabilidades de segurança potenciais. Também complica o cumprimento das leis de proteção e privacidade de dados. O acesso não autorizado e ameaças cibernéticas são preocupações maiores agora.
5#Sharding (Escalabilidade Horizontal)
O sharding de banco de dados também é uma forma de escalar um banco de dados. Ele divide os dados em segmentos, chamados shards, e os armazena em servidores separados. Isso distribui a carga de trabalho, melhorando tanto o desempenho quanto a escalabilidade. Além disso, o sharding melhora a tolerância a falhas. Permite que o sistema funcione mesmo se um shard ou servidor falhar. Isso torna-o uma solução resistente.
O sharding é frequentemente usado em aplicações em nuvem como SaaS. Permite que múltiplos clientes acessem grandes conjuntos de dados. Também pode ser organizado com base no tempo para cenários como ingestão de dados de dispositivos distribuídos. O sharding funciona melhor quando as transações usam uma única chave de sharding. Isso otimiza o desempenho das consultas e minimiza a comunicação entre shards.

Vantagens do Sharding
-
Desempenho Melhorado: O sharding espalha os dados em múltiplos servidores. Isso reduz a carga em cada servidor e acelera as respostas das consultas.
-
Capacidade Aumentada: Sharding permite escalabilidade fácil. À medida que os dados crescem, podemos adicionar servidores para aumentar a capacidade do banco de dados sem prejudicar o desempenho.
-
Isolamento de Falhas: Se um shard falhar, apenas alguns dados serão perdidos. O restante do sistema continua operacional. Isso melhora a resiliência.
Contras do Sharding
-
O Sharding é Intricado: Requer planejamento cuidadoso. Você deve decidir como distribuir os dados, quantos shards criar e como rotear as consultas para o shard correto.
-
Desafios na Distribuição de Dados: Garantir que os dados sejam distribuídos uniformemente entre os shards pode ser difícil. Se os dados forem distribuídos de forma desigual, alguns shards podem ficar sobrecarregados, anulando os benefícios de desempenho do sharding.
-
Junção de Dados Complexa: A junção de dados entre múltiplos shards pode ser lenta e complicada. Isso pode prejudicar o desempenho das consultas.
6#Escalabilidade Vertical
Escalabilidade vertical, ou "escalonamento para cima," adiciona recursos a um único servidor quando ele não consegue atender à demanda. Isso significa adicionar CPU, memória ou armazenamento. Este processo atualiza o hardware do servidor existente para melhorar sua capacidade.
A escalabilidade vertical é uma solução rápida e simples. Isso é verdade para bancos de dados baseados em nuvem. Você pode aumentar os recursos ajustando as configurações do servidor. É ideal quando podemos melhorar o desempenho apenas expandindo os recursos do servidor. Não precisamos distribuir a carga entre múltiplos servidores.
Prós da Escalabilidade Vertical
-
Divisão Racional: Sharding vertical divide uma tabela em subconjuntos menores e relacionados. Eles podem ser gerenciados independentemente. Isso permite um uso melhor dos recursos e desempenho em partes do banco de dados.
-
Fácil de Implementar: A escalabilidade vertical é mais simples do que a horizontal. Não requer mudanças na arquitetura do aplicativo ou na gestão de sistemas distribuídos.
-
Menor Latência de Rede: Todos os recursos estão em um único servidor. Isso minimiza a latência de rede e melhora os tempos de resposta.
-
Uso Eficiente de Recursos: Atualizar um único servidor maximiza seus recursos. Para alguns tipos de carga de trabalho, isso torna a escalabilidade vertical mais eficiente do que usar múltiplos servidores.
Contras da Escalabilidade Vertical
-
Carga Desbalanceada: Alguns shards podem receber mais tráfego do que outros. Isso pode reduzir a eficiência do sistema.
-
Complexidade na Gestão: Gerenciar múltiplos shards torna as tarefas mais complexas. Essas incluem manutenção, backups e sincronização. Cada shard opera de forma independente e requer mais supervisão.
-
Capacidade Limitada: A escalabilidade vertical tem limites físicos. Uma vez que um servidor atinge sua capacidade máxima, outros métodos de escalabilidade devem ser explorados.
-
Consultas Complexas: Consultar ou unir dados entre múltiplos shards pode ser ineficiente e complexo, exigindo coordenação entre os shards.
-
Ponto Único de Falha: Como todas as operações dependem de um único servidor, qualquer falha nesse servidor pode causar o desligamento de toda a aplicação.
7#Visões Materializadas
Na computação, uma visão materializada é um objeto de banco de dados. Ela armazena os resultados de uma consulta em disco. Isso em vez de recalcular os resultados toda vez que a consulta for executada. Esse processo de criar uma visão materializada é conhecido como materialização. Visões materializadas melhoram o desempenho. Elas permitem a recuperação rápida de dados pré-calculados.

Prós de Visões Materializadas
-
Desempenho de Consulta Melhorado: Visões materializadas armazenam resultados de consultas pré-calculados. Isso reduz o tempo necessário para recuperar dados complexos. Isso é especialmente benéfico para consultas envolvendo grandes conjuntos de dados ou cálculos complexos, como agregações.
-
Consumo Reduzido de Recursos: Visões materializadas armazenam em cache os resultados de consultas intensivas em recursos. Isso reduz a necessidade de execução repetida de consultas e diminui o uso de CPU, memória e E/S.
-
Acesso Mais Rápido a Dados Agregados: Visões materializadas são perfeitas para armazenar os resultados de consultas de agregação que são frequentemente executadas. Elas permitem acesso mais rápido a informações resumidas.
-
Redução da Carga de Trabalho: Elas podem reduzir a computação pesada das consultas em tempo real. Isso melhora o desempenho do banco de dados espalhando a carga de trabalho ao longo do tempo.
-
Dados Visuais: Visões materializadas fornecem um instantâneo dos dados. Isso é no momento da criação ou da última atualização. Isso é útil para análise histórica ou relatórios.
Contras das Visões Materializadas
-
Funcionalidade Restrita: Após criar uma visão materializada, você não pode alterar sua definição SQL. Você também não pode substituí-la por outra visão com o mesmo nome. Visões materializadas também não podem consultar tabelas externas, com wildcards ou visões lógicas. Elas suportam apenas um conjunto limitado de funções SQL. Isso as torna menos flexíveis para consultas complexas. Além disso, elas não podem ser aninhadas em outras visões materializadas, limitando seu uso em modelagem de dados avançada.
-
Manipulação Direta de Dados Limitada: Você não pode atualizar os dados de uma view materializada usando COPY, EXPORT, LOAD ou operações DML. Isso reduz a flexibilidade no gerenciamento dos dados da view.
-
Custo de Manutenção: Para sincronizar uma view materializada com os dados básicos, são necessárias atualizações periódicas. Esse processo de atualização pode criar alto custo de sistema e consumir recursos. Isso depende do tamanho do conjunto de dados e da frequência das atualizações.
-
Atualizações Frequentes Aumentam a Complexidade: É mais difícil manter views materializadas quando os dados de origem mudam com frequência. As atualizações devem ser coordenadas cuidadosamente com as tabelas base para evitar inconsistências. Isso adiciona complexidade ao processo de gerenciamento.
Por que Você Deve Ter um Banco de Dados Escalável

Escala é a capacidade de um sistema de se adaptar a demandas em mudança. Ele deve gerenciar dados crescentes e usuários eficientemente. Aqui estão alguns motivos importantes por que ter um banco de dados escalável é essencial para o seu negócio:
-
Melhoria na Colaboração: Um banco de dados escalável é um repositório central e seguro. Ele permite que todos os membros da equipe acessem os dados do projeto. Isso melhora a tomada de decisão e simplifica os fluxos de trabalho. Isso é feito permitindo um compartilhamento e colaboração melhores dos dados.
-
Suporta Múltiplas Fontes de Dados: Organizações grandes devem integrar dados de múltiplos canais. Um banco de dados escalável consolida essas fontes em um hub unificado e centralizado, tornando mais fácil gerenciar fluxos de informações diversos.
-
Gestiona o Crescimento de Forma Eficiente: À medida que seu negócio cresce, seus dados e solicitações de usuários também aumentarão. Um banco de dados escalável pode se ajustar facilmente a esse crescimento. Ele evitará reestruturações frequentes do sistema e manterá o negócio em funcionamento.
-
Gestiona Picos Súbitos de Tráfego: Eventos de alto tráfego, como feriados ou promoções, podem causar picos na atividade dos usuários em sistemas empresariais. Um banco de dados escalável pode aumentar rapidamente sua capacidade. Ele manterá o sistema estável durante os picos de tráfego.
-
Melhora o Desempenho: Bancos de dados escaláveis otimizam o uso de recursos, evitando lentidões sob cargas pesadas. Eles permitem consultas rápidas, armazenamento e processamento de dados. Isso melhora os tempos de resposta e mantém o sistema confiável.
-
Melhora A Experiência do Usuário: Um banco de dados escalável mantém seu sistema estável. Ele evita travamentos ou interrupções, independentemente de quantos usuários sua empresa tenha. Isso leva a uma experiência do usuário mais suave e satisfatória.
Conclusão
Escala de banco de dados é crucial para armazenamento eficiente de dados e melhoria no desempenho de sistemas de software. Desde indexação e denormalização até cache de dados, replicação, sharding, escalonamento vertical e views materializadas, existem diversas estratégias para escolher com base nas necessidades do seu sistema.
Cada abordagem para escala de banco de dados vem com seus próprios benefícios e desafios únicos. Em 2025, é crucial escolher a estratégia que melhor se alinhe aos seus objetivos de negócios e infraestrutura.
Escrito por
Kimmy
Publicado em
15 de abr. de 2026
Compartilhar artigo
Leia mais
Experiências
10 Dicas de Design de Interface Web para Seu Próximo Site (atualizado em 2024)
14 de abr. de 2026
Nosso último blog
Experiências
25 de mai. de 2026
Guia do Viajante: Os 10 Melhores Sites de Hotéis para um Planejamento Perfeito
Prédio de IA
25 de mai. de 2026
Os 10 Melhores Criadores de Portfólio para Designers de UX: Mostre Seu Trabalho
Páginas da web em um minuto, alimentadas pela Wegic!
Com a Wegic, transforme suas necessidades em sites impressionantes e funcionais com IA avançada
Teste grátis com a Wegic, construa seu site com um clique!
Que tipo de site você deseja criar?