Accedi
Costruisci il tuo sito
Scalabilità del database: strategie e migliori pratiche (aggiornato 2025)
Per aumentare il traffico e migliorare il flusso dei dati, abbiamo compilato strategie e migliori pratiche per aiutarti a ottimizzare la scalabilità del database. Prova ora.

La tua azienda ha difficoltà a gestire le crescenti richieste e a gestire in modo efficace i dati e gli utenti in aumento? Potrebbe essere il momento di scalare il tuo database. In questo articolo scoprirai passaggi pratici per ottimizzare il tuo sistema sovraccarico e prepararlo per la crescita futura.

Cosa è la scalabilità del database
Un database è una raccolta organizzata di dati, spesso detta dati strutturati, che possono essere memorizzati e accessibili su un sistema informatico. I database sono progettati specificamente per gestire, archiviare e recuperare informazioni in modo efficiente. Un Sistema di Gestione di Database (DBMS) controlla di solito un database. Facilita l'accesso, la gestione e l'aggiornamento dei dati nel database.
Scalabilità del database significa adattare la dimensione e la capacità di un database. Questo per soddisfare le crescenti richieste, come più dati e utenti. Deve mantenere le prestazioni, la risposta e la affidabilità. Costruire un database scalabile garantisce un'esperienza utente senza interruzioni, anche quando il sistema si espande.
Scalabilità del database: strategie e migliori pratiche (aggiornato 2025)
Pronto a ottimizzare il tuo database per la crescita e le prestazioni? Ho raccolto strategie chiave e migliori pratiche per aiutarti a scalare il tuo database in modo efficace.
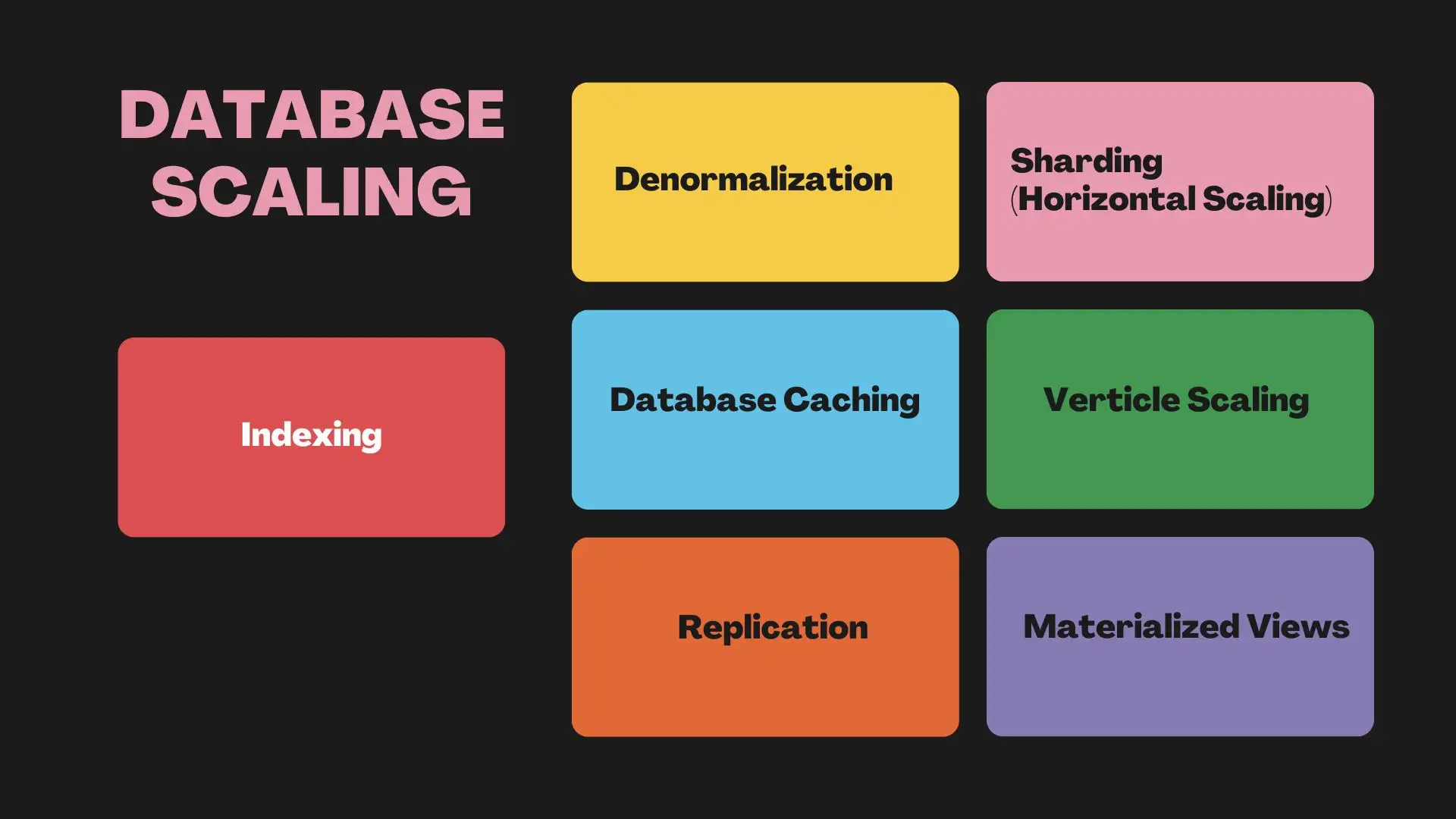
1#Indicizzazione
L'indicizzazione del database è essenziale per la scalabilità del database. Essa accelera il recupero dei dati permettendo ricerche più rapide. È come un indice di un libro, che aiuta a trovare gli argomenti senza sfogliare ogni pagina. Sebbene gli indici migliorino l'efficienza delle ricerche, richiedono uno spazio aggiuntivo e operazioni di scrittura per mantenerli.
Pratiche chiave includono l'analisi e l'ottimizzazione regolari delle query, l'utilizzo di pool di connessioni per una gestione efficiente, la suddivisione di tabelle grandi e la scelta del tipo di database giusto (SQL vs. NoSQL). Considera la dimensione degli indici, la velocità di ricerca, la manutenzione e la tolleranza agli errori quando si progettano gli indici. Insieme, questi fattori aiutano a migliorare l'efficienza e le prestazioni complessive del database.
2#Denormalizzazione
La denormalizzazione è una delle tecniche di scalabilità del database per l'ottimizzazione. Migliora le prestazioni di lettura aggiungendo dati ridondanti a uno schema precedentemente normalizzato. Aiuta a ridurre il costo di accesso che potrebbe aumentare a causa di più join di tabelle in un database normalizzato, specialmente quando si lavora con tabelle e indici grandi.
La denormalizzazione velocizza le query da aggiungendo ridondanza precalcolata. Tuttavia, aumenta lo spazio di archiviazione e può causare incoerenze nei dati. Tecniche comuni includono la divisione delle tabelle e l'aggiunta di colonne derivate o ridondanti. L'uso di tabelle replicate è anche comune. Non confondere questo processo con un database che non è mai stato normalizzato. La denormalizzazione viene solitamente effettuata dopo che uno schema è stato ottimizzato tramite la normalizzazione.
Vantaggi della denormalizzazione
-
Migliore scalabilità: La denormalizzazione può rendere i sistemi database più scalabili. Lo fa riducendo il numero di tabelle e migliorando le prestazioni. La denormalizzazione riduce il numero di transazioni del database quando si leggono i dati. Questo numero ridotto di transazioni può adattarsi a diversi carichi utente, migliorando così la scalabilità dell'applicazione.
-
Ridotta complessità: La denormalizzazione può semplificare lo schema del database. Lo fa riducendo le query di join e unendo dati correlati in meno tabelle. Uno schema più semplice è più facile da comprendere, interrogare e gestire. Inoltre, questa semplicità aiuta a ridurre significativamente gli errori relativi alle operazioni del database.
-
Migliore velocità delle query: La denormalizzazione aumenta la velocità delle query riducendo i join. A seconda delle esigenze, interrogare un archivio dati normalizzato può richiedere più join di diverse tabelle.
Svantaggi della denormalizzazione:
-
Ridotta integrità dei dati: La denormalizzazione introduce dati ridondanti. Questo aumenta il rischio di incoerenze. Gli aggiornamenti potrebbero non propagarsi correttamente in tutti i campi ridondanti.
-
Maggiore complessità: La denormalizzazione può semplificare alcune query. Ma può anche complicare il database creando dati duplicati. Questo può portare a discrepanze tra i set di dati, specialmente in scenari che coinvolgono database replicati.
-
Necessità di spazio di archiviazione e costi più elevati: La denormalizzazione crea dati ridondanti. Tecniche come la duplicazione dei dati e la replicazione delle tabelle occupano spazio. Questo aumenta i costi di archiviazione, che possono essere elevati per grandi set di dati.
-
Più aggiornamenti e minore flessibilità: Con dati ridondanti, la frequenza degli aggiornamenti aumenta, complicando la manutenzione del database. Questo, a sua volta, limita la flessibilità del sistema, rendendolo più difficile da adattare a nuove esigenze o modifiche.
3#Caching del database
La cache del database è anche una delle tecniche per la scalabilità del database. Memorizza i dati più frequentemente acceduti in memoria. Questo riduce la necessità di query e calcoli ripetuti sul database. Questo metodo migliora la scalabilità e le prestazioni dell'applicazione. Riduce il tempo impiegato per recuperare i dati dalla memoria persistente, come dischi rigidi o SSD.

Vantaggi del database caching
-
Carico ridotto sul database: La cache sposta le query frequenti dal database. Questo riduce la pressione sulle risorse del server. Consente al database di gestire più richieste in modo efficiente.
-
Miglioramento delle prestazioni: La cache memorizza i dati più frequentemente acceduti in memoria. Riduce drasticamente i tempi di risposta e velocizza il recupero dei dati.
-
Ridotta latenza: I dati in cache sono in strutture in memoria veloci. Questo minimizza la latenza e velocizza i tempi di risposta per gli utenti e le applicazioni.
-
Meno operazioni di I/O su disco: La cache riduce le letture su disco. Questo velocizza l'accesso ai dati ed è più efficiente rispetto alla memorizzazione su disco.
Svantaggi del database caching
-
Invalidazione della cache: È difficile sapere quando aggiornare i dati in cache. Tuttavia, è cruciale per la coerenza dei dati.
-
Costo più alto della cache esterna: La cache esterna richiede spesso DRAM. È più costosa rispetto all'uso di SSD o HDD per lo storage.
-
Minore disponibilità: Le cache esterne hanno generalmente una disponibilità (HA) più bassa rispetto ai database. Questo può causare malfunzionamenti e sovraccaricare il database durante gli outage della cache.
-
Interferenza con la cache del database: Una cache esterna può danneggiare la cache interna del database. Questo ne riduce l'efficacia e aumenta l'accesso al disco.
4#Replicazione
Ora introdurrò un'altra tecnica per la scalabilità del database: la replicazione. La replicazione del database copia il database e lo memorizza in vari luoghi locali o in cloud. Questo garantisce l'accessibilità dei dati, la tolleranza ai guasti e la affidabilità. Consente agli utenti di accedere agli stessi dati aggiornati, migliorando le prestazioni del sistema e la capacità di recupero da disastri. La replicazione avviene di solito in tempo reale mentre i dati vengono creati, aggiornati o eliminati, ma può anche essere effettuata una tantum o come processo batch pianificato.

Vantaggi della replicazione
-
Miglioramento del recupero da disastri: La replicazione dei dati crea copie del database in diversi luoghi. Questo garantisce alta disponibilità e accesso durante gli interventi per disastri.
-
Carico ridotto sui server: La replicazione sposta i dati in un ambiente replicato. Questo riduce il carico sul database principale. Ottimizza le prestazioni e libera le risorse.
-
Miglioramento dell'analisi dei dati: La replicazione crea ambienti isolati per eseguire query complesse. Questo permette agli analisti di esplorare i dati senza influenzare i sistemi principali.
-
Intelligenza aziendale in tempo reale: La replicazione consente l'accesso ai dati in tempo reale tra le unità aziendali. Questo migliora la precisione dei report e la capacità di decisione. Integra inoltre i dati da diverse fonti per un'ottima intelligenza aziendale.
-
Supporto per applicazioni AI/ML: I database replicati forniscono set di dati coerenti e aggiornati per addestrare modelli AI/ML. Questo migliora la precisione delle previsioni e consente applicazioni in tempo reale basate sui dati.
Svantaggi della replicazione dei dati
-
Rischio di compromissione dei dati: Errori nella replicazione possono corrompere o perdere dati. Questo rappresenta un rischio significativo per l'integrità dei dati.
-
Costi aumentati: La replicazione dei dati richiede immagazzinamento e trasferimento di molte copie dei dati. Richiede molto spazio e banda. Questo comporta costi più elevati per lo storage e l'operazione, inclusa la necessità di personale aggiuntivo per monitorare e gestire il processo.
-
Rischi per la sicurezza dei dati: La replicazione dei dati, specialmente su server remoti, introduce vulnerabilità di sicurezza. Complica inoltre il rispetto delle normative sulla protezione e privacy dei dati. L'accesso non autorizzato e le minacce informatiche sono preoccupazioni maggiori ora.
5#Sharding (scalabilità orizzontale)
Il sharding del database è anche un modo per scalare un database. Suddivide i dati in segmenti, chiamati shard, e li memorizza su server diversi. Questo distribuisce il carico di lavoro, migliorando le prestazioni e la scalabilità. Inoltre, il sharding migliora la tolleranza ai guasti. Consente al sistema di funzionare anche se uno shard o un server fallisce. Questo lo rende una soluzione resiliente.
Il sharding viene spesso utilizzato in applicazioni cloud come SaaS. Consente a più tenant di accedere a grandi set di dati. Può anche essere organizzato in base al tempo per scenari come l'ingresso dei dati da dispositivi distribuiti. Il sharding funziona meglio quando le transazioni utilizzano una singola chiave di sharding. Questo ottimizza le prestazioni delle query e riduce la comunicazione tra shard.

Vantaggi del sharding
-
Miglioramento delle prestazioni: Il sharding distribuisce i dati su diversi server. Riduce il carico su ciascun server e velocizza le risposte alle query.
-
Capacità aumentata: La suddivisione in shard permette una scalabilità semplice. Man mano che i dati crescono, possiamo aggiungere server per aumentare la capacità del database senza compromettere le prestazioni.
-
Isole di guasto: Se un shard fallisce, si perde solo una parte dei dati. Il resto del sistema rimane operativo. Questo migliora la resilienza.
Contro della suddivisione in shard
-
La suddivisione in shard è complessa: Richiede una pianificazione attenta. Bisogna decidere come distribuire i dati, quanti shard creare e come instradare le query al shard corretto.
-
Difficoltà nella distribuzione dei dati: Garantire una distribuzione equa dei dati tra i shard può essere difficile. Se i dati non sono distribuiti in modo uniforme, alcuni shard potrebbero diventare sovraccarichi, annullando i vantaggi prestazionali della suddivisione in shard.
-
Complessità nel join dei dati: Unire i dati tra più shard può essere lento e complicato. Può danneggiare le prestazioni delle query.
6#Scala verticale
La scalabilità verticale, o "scala in alto," aggiunge risorse a un singolo server quando non riesce a soddisfare la domanda. Questo significa aggiungere CPU, memoria o archiviazione. Questo processo aggiorna l'hardware del server esistente per migliorarne la capacità.
La scalabilità verticale è una soluzione veloce e semplice. Questo è vero per i database basati sul cloud. Spesso è possibile aumentare le risorse modificando le impostazioni del server. È ideale quando possiamo migliorare le prestazioni aumentando semplicemente le risorse del server. Non dovremmo dover distribuire il carico su più server.
Vantaggi della scalabilità verticale
-
Divisione ragionevole: La suddivisione verticale divide una tabella in sottinsiemi più piccoli e correlati. Possono essere gestiti in modo indipendente. Questo permette un uso migliore delle risorse e delle prestazioni in alcune parti del database.
-
Semplice da implementare: La scalabilità verticale è più semplice della scalabilità orizzontale. Non richiede modifiche all'architettura dell'app o alla gestione di sistemi distribuiti.
-
Minore latenza di rete: Tutte le risorse si trovano su un singolo server. Questo riduce la latenza di rete e migliora i tempi di risposta.
-
Utilizzo efficiente delle risorse: Aggiornare un singolo server massimizza le sue risorse. Per alcuni carichi di lavoro, questo rende la scalabilità verticale più efficiente rispetto all'uso di più server.
Contro della scalabilità verticale
-
Carico sproporzionato: Alcuni shard possono ricevere più traffico degli altri. Questo può ridurre l'efficienza del sistema.
-
Complessità nella gestione: La gestione di più shard rende le attività più complesse. Queste includono manutenzione, backup e sincronizzazione. Ogni shard funziona in modo indipendente e richiede più supervisione.
-
Capacità limitata: La scalabilità verticale ha limiti fisici. Una volta che un server raggiunge la sua capacità massima, devono essere esplorati altri metodi di scalabilità.
-
Query complesse: Eseguire query o unire dati tra più shard può essere inefficiente e complesso, richiedendo una coordinazione tra gli shard.
-
Punto di fallimento unico: Poiché tutte le operazioni dipendono da un singolo server, un guasto di quel server potrebbe causare il blocco dell'intera applicazione.
7#Viste materializzate
Nel calcolo, una vista materializzata è un oggetto del database. Memorizza i risultati di una query su disco. Questo invece di ricalcolare i risultati ogni volta che la query viene eseguita. Questo processo di creazione di una vista materializzata è noto come materializzazione. Le viste materializzate migliorano le prestazioni. Consentono un accesso rapido a dati precalcolati.

Vantaggi delle viste materializzate
-
Miglioramento delle prestazioni delle query: Le viste materializzate memorizzano i risultati delle query precalcolati. Questo riduce il tempo necessario per recuperare dati complessi. Questo è particolarmente vantaggioso per le query che coinvolgono grandi set di dati o calcoli complessi, come aggregazioni.
-
Consumo ridotto di risorse: Le viste materializzate memorizzano i risultati di query che richiedono molte risorse. Questo riduce la necessità di eseguire nuovamente le query e riduce l'uso di CPU, memoria e I/O.
-
Accesso più rapido ai dati aggregati: Le viste materializzate sono perfette per memorizzare i risultati di query di aggregazione eseguite frequentemente. Consentono un accesso più veloce alle informazioni riassuntive.
-
Scarico del carico di lavoro: Possono scaricare calcoli pesanti dalle query sui dati live. Questo migliora le prestazioni del database distribuendo il carico nel tempo.
-
Dati visivi: Le viste materializzate forniscono uno screenshot dei dati. Al momento della creazione o dell'ultimo aggiornamento. Questo è utile per l'analisi storica o la generazione di report.
Contro delle viste materializzate
-
Funzionalità limitata: Dopo la creazione di una vista materializzata, non è possibile modificare la sua definizione SQL. Non è inoltre possibile sostituirla con un'altra vista dello stesso nome. Le viste materializzate non possono neppure interrogare tabelle esterne, wildcard o viste logiche. Supportano solo un insieme limitato di funzioni SQL. Questo le rende meno flessibili per query complesse. Inoltre, non possono essere annidate all'interno di altre viste materializzate, limitando il loro utilizzo nel modellamento avanzato dei dati.
-
Manipolazione diretta dei dati limitata: Non puoi aggiornare i dati di una vista materializzata utilizzando COPY, EXPORT, LOAD o operazioni DML. Questo riduce la flessibilità nella gestione dei dati della vista.
-
Carico di manutenzione: Per sincronizzare una vista materializzata con i dati di base, sono necessari aggiornamenti periodici. Questo processo di aggiornamento può creare un alto carico sul sistema e consumare risorse. Dipende dalla dimensione del set di dati e dalla frequenza degli aggiornamenti.
-
Aggiornamenti frequenti aumentano la complessità: È più difficile mantenere le viste materializzate quando i dati di origine cambiano spesso. Gli aggiornamenti devono essere coordinati con attenzione con le tabelle di base per evitare incoerenze. Questo aggiunge complessità al processo di gestione.
Perché dovresti avere un database scalabile

La scalabilità è la capacità di un sistema di adattarsi alle richieste in costante cambiamento. Deve gestire dati e utenti in crescita in modo efficiente. Ecco alcuni motivi chiave per cui avere un database scalabile è essenziale per la tua azienda:
-
Migliore collaborazione: Un database scalabile è un archivio centrale e sicuro. Consente a tutti i membri del team di accedere ai dati del progetto. Migliora la decisione e semplifica i flussi di lavoro. Lo fa permettendo un miglior condivisione e collaborazione dei dati.
-
Supporta più fonti di dati: Le grandi organizzazioni devono integrare dati da più canali. Un database scalabile consolida queste fonti in un hub unificato e centralizzato, rendendo più facile gestire flussi di informazioni diversi.
-
Gestisce la crescita in modo efficiente: Man mano che la tua azienda si espande, cresceranno anche i tuoi dati e le richieste degli utenti. Un database scalabile può adattarsi facilmente a questa crescita. Eviterà aggiornamenti frequenti del sistema e manterrà l'azienda in funzione.
-
Gestisce picchi improvvisi di traffico: Eventi ad alto traffico, come le vacanze o le promozioni, possono far aumentare improvvisamente l'attività degli utenti nei sistemi aziendali. Un database scalabile può aumentare rapidamente la capacità. Manterrà il sistema stabile durante i picchi di traffico.
-
Migliora le prestazioni: I database scalabili ottimizzano l'utilizzo delle risorse, evitando rallentamenti delle prestazioni sotto carichi pesanti. Consentono query, archiviazione e elaborazione dei dati veloci. Questo migliora i tempi di risposta e mantiene il sistema affidabile.
-
Migliora l'esperienza utente: Un database scalabile mantiene il tuo sistema stabile. Evita ritardi o interruzioni, indipendentemente dal numero di utenti che la tua azienda ha. Questo porta a un'esperienza utente più fluida e soddisfacente.
Conclusione
La scalabilità del database è cruciale per una conservazione efficiente dei dati e per migliorare le prestazioni del sistema software. Dall'indicizzazione e dalla denormalizzazione al caching dei dati, alla replica, al partizionamento, alla scalabilità verticale e alle viste materializzate, esistono diverse strategie da scegliere in base alle esigenze del tuo sistema.
Ogni approccio alla scalabilità del database ha i propri vantaggi e sfide unici. Nel 2025, è fondamentale scegliere la strategia che meglio si allinea ai tuoi obiettivi aziendali e alla tua infrastruttura.
Scritto da
Kimmy
Pubblicato il
15 apr 2026
Condividi articolo
Leggi di più
Il nostro ultimo blog
Pagine web in un minuto, alimentate da Wegic!
Con Wegic, trasforma le tue esigenze in siti web straordinari e funzionali con l'AI avanzata
Prova gratuita con Wegic, crea il tuo sito in un clic!
Che tipo di sito web vuoi creare?