Escalabilidad de bases de datos: Estrategias y mejores prácticas (Actualizado 2025)
Para generar más tráfico y mejorar el flujo de datos, hemos recopilado estrategias y mejores prácticas para ayudarte a optimizar la escalabilidad de la base de datos. Prueba ahora.


¿Qué es la escalabilidad de bases de datos
Escalabilidad de bases de datos: Estrategias y mejores prácticas (Actualizado 2025)
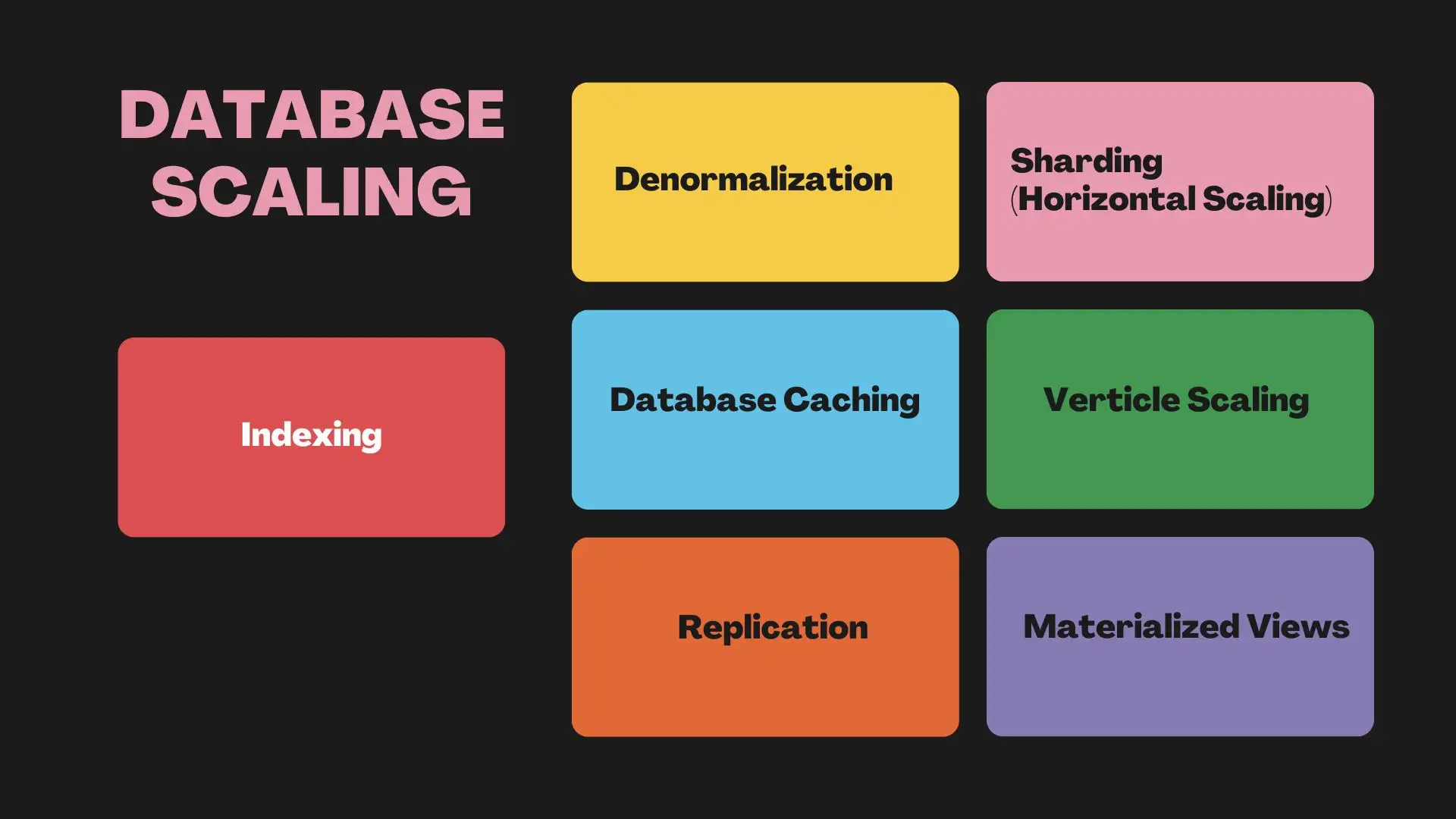
1#Indexación
2#Denormalización
Ventajas de la denormalización
-
Mejor escalabilidad: La denormalización puede hacer que los sistemas de bases de datos sean más escalables. Lo hace reduciendo el número de tablas y mejorando el rendimiento. La denormalización reduce el número de transacciones de base de datos al leer datos. Este número reducido de transacciones puede adaptarse a diferentes cargas de usuarios, mejorando así la escalabilidad de la aplicación.
-
Menor complejidad: La denormalización puede simplificar el esquema de la base de datos. Lo hace reduciendo las consultas de unión y combinando datos relacionados en menos tablas. Un esquema más simple es más fácil de entender, consultar y gestionar. Además, esta simplicidad ayudará significativamente a reducir errores relacionados con las operaciones de la base de datos.
-
Mejor rendimiento de consultas: La denormalización mejora la velocidad de las consultas al reducir las uniones. Dependiendo de los requisitos, consultar una tienda de datos normalizados puede requerir múltiples uniones de diferentes tablas.
Desventajas de la denormalización:
-
Menor integridad de los datos: La denormalización introduce datos redundantes. Esto aumenta el riesgo de inconsistencias. Las actualizaciones pueden no propagarse correctamente en todos los campos redundantes.
-
Mayor complejidad: La denormalización puede simplificar algunas consultas. Pero también puede complicar la base de datos al crear datos duplicados. Esto puede llevar a discrepancias entre conjuntos de datos, especialmente en escenarios que involucran bases de datos reflejadas.
-
Mayores necesidades de almacenamiento y costos: La denormalización crea datos redundantes. Las técnicas como la duplicación de datos y la duplicación de tablas ocupan espacio. Esto incrementa los costos de almacenamiento, que pueden ser altos para grandes conjuntos de datos.
-
Más actualizaciones y menor flexibilidad: Con datos redundantes, la frecuencia de actualizaciones aumenta, complicando el mantenimiento de la base de datos. Esto, a su vez, limita la flexibilidad del sistema, haciendo más difícil adaptarse a requisitos o modificaciones cambiantes.
3#Caché de base de datos

Ventajas del caché de bases de datos
-
Carga reducida en la base de datos: El caché descarga consultas frecuentes de la base de datos. Esto reduce la presión sobre los recursos del servidor. Permite que la base de datos maneje más solicitudes de manera eficiente.
-
Mejora del rendimiento: El caché almacena datos frecuentemente accedidos en memoria. Esto reduce drásticamente los tiempos de respuesta y acelera la recuperación de datos.
-
Menor latencia: Los datos en caché están en estructuras de memoria rápida. Esto minimiza la latencia y acelera los tiempos de respuesta para usuarios y aplicaciones.
-
Menor número de operaciones de E/S en disco: El caché reduce las lecturas en disco. Esto acelera el acceso a los datos y es más eficiente que el almacenamiento basado en disco.
Desventajas del caché de bases de datos
-
Invalidación de caché: Es difícil saber cuándo actualizar los datos en caché. Pero es crítico para la consistencia de los datos.
-
Mayor costo del caché externo: El caché externo suele requerir DRAM. Es más caro que usar SSD o HDD para el almacenamiento.
-
Menor disponibilidad: Los cachés externos suelen tener menor alta disponibilidad (HA) que las bases de datos. Esto puede causar fallos y estrés en la base de datos durante interrupciones del caché.
-
Interferencia con el caché de la base de datos: Un caché externo puede interrumpir el caché interno de la base de datos. Esto lo hace menos efectivo y aumenta el acceso al disco.
4#Replicación

Ventajas de la replicación
-
Mejor recuperación ante desastres: La replicación de datos crea copias de la base de datos en múltiples ubicaciones. Esto asegura alta disponibilidad y acceso durante interrupciones causadas por desastres.
-
Reducción de la carga en el servidor: La replicación descarga datos a un entorno replicado. Esto reduce la carga en la base de datos principal. Esto optimiza el rendimiento y libera recursos.
-
Mejora del análisis de datos: La replicación crea entornos aislados para ejecutar consultas complejas. Esto permite a los analistas explorar datos sin afectar los sistemas principales.
-
Inteligencia de negocios en tiempo real: La replicación permite el acceso a datos en tiempo real en unidades de negocio. Esto mejora la precisión de informes y la toma de decisiones. También integra datos de diversas fuentes para una mejor inteligencia de negocios.
-
Soporte para aplicaciones de IA/ML: Las bases de datos replicadas proporcionan conjuntos de datos consistentes y actualizados para entrenar modelos de IA/ML. Esto mejora la precisión predictiva y permite aplicaciones en tiempo real basadas en datos.
Desventajas de la replicación de datos
-
Riesgo de compromiso de datos: Errores en la replicación pueden corromper o perder datos. Esto representa un riesgo significativo para la integridad de los datos.
-
Costos incrementados: La replicación de datos requiere almacenar y transferir múltiples copias de datos. Necesita mucho almacenamiento y ancho de banda. Esto resulta en mayores costos de almacenamiento y operación, incluyendo la necesidad de personal adicional para supervisar y gestionar el proceso.
-
Riesgos de seguridad de datos: La replicación de datos, especialmente en servidores remotos, introduce vulnerabilidades de seguridad potenciales. También complica el cumplimiento de leyes de protección y privacidad de datos. El acceso no autorizado y las amenazas cibernéticas son mayores preocupaciones ahora.
5#Fragmentación (Escalado horizontal)

Ventajas de la fragmentación
-
Mejora del rendimiento: La fragmentación distribuye los datos en múltiples servidores. Reduce la carga en cada servidor y acelera las respuestas a las consultas.
-
Capacidad aumentada: La partición permite una escalabilidad sencilla. A medida que los datos crecen, podemos agregar servidores para aumentar la capacidad de la base de datos sin afectar el rendimiento.
-
Aislamiento de fallos: Si un fragmento falla, solo se pierde algo de datos. El resto del sistema sigue operativo. Esto mejora la resiliencia.
Contras de la partición
-
La partición es compleja: Requiere un plan cuidadoso. Debes decidir cómo distribuir los datos, cuántos fragmentos crear y cómo enrutar las consultas al fragmento correcto.
-
Desafíos de distribución de datos: Asegurar que los datos estén distribuidos de manera equilibrada entre los fragmentos puede ser difícil. Si los datos no están distribuidos de forma equilibrada, algunos fragmentos pueden sobrecargarse, anulando los beneficios de rendimiento de la partición.
-
Unión de datos compleja: Unir datos entre múltiples fragmentos puede ser lento y complicado. Puede afectar el rendimiento de las consultas.
6#Escalado vertical
Pros de escalado vertical
-
División razonable: La partición vertical divide una tabla en subconjuntos más pequeños y relacionados. Pueden ser gestionados de forma independiente. Esto permite un mejor uso de los recursos y el rendimiento en partes de la base de datos.
-
Fácil de implementar: El escalado vertical es más sencillo que el escalado horizontal. No requiere cambios en la arquitectura de la aplicación ni en la gestión de sistemas distribuidos.
-
Menor latencia de red: Todos los recursos están en un solo servidor. Esto minimiza la latencia de red y mejora los tiempos de respuesta.
-
Uso eficiente de los recursos: Actualizar un solo servidor maximiza sus recursos. Para algunos cargas de trabajo, esto hace que el escalado vertical sea más eficiente que usar múltiples servidores.
Contras de escalado vertical
-
Carga desequilibrada: Algunos fragmentos pueden recibir más tráfico que otros. Esto puede reducir la eficiencia del sistema.
-
Complejidad de gestión: Gestionar múltiples fragmentos hace que las tareas sean más complejas. Estas incluyen mantenimiento, copias de seguridad y sincronización. Cada fragmento opera de forma independiente y requiere más supervisión.
-
Capacidad limitada: El escalado vertical tiene límites físicos. Una vez que un servidor alcanza su capacidad máxima, se deben explorar otros métodos de escalado.
-
Consultas complejas: Consultar o unir datos entre múltiples fragmentos puede ser ineficiente y complejo, requiriendo coordinación entre los fragmentos.
-
Punto único de fallo: Dado que todas las operaciones dependen de un solo servidor, cualquier fallo de ese servidor podría hacer que toda la aplicación se detenga.
7#Vistas materializadas

Pros de vistas materializadas
-
Mejora del rendimiento de consultas: Las vistas materializadas almacenan resultados de consultas precalculados. Esto reduce el tiempo necesario para recuperar datos complejos. Esto es especialmente beneficioso para consultas que involucran grandes conjuntos de datos o cálculos complejos, como agregaciones.
-
Consumo reducido de recursos: Las vistas materializadas almacenan en caché los resultados de consultas intensivas en recursos. Esto reduce la necesidad de ejecutar consultas repetidamente y disminuye el uso de CPU, memoria e I/O.
-
Acceso más rápido a datos agregados: Las vistas materializadas son ideales para almacenar los resultados de consultas de agregación que se ejecutan con frecuencia. Permiten un acceso más rápido a información resumida.
-
Reducción de carga: Pueden reducir la computación intensa de consultas en datos en vivo. Esto mejora el rendimiento de la base de datos al distribuir la carga de trabajo con el tiempo.
-
Datos visuales: Las vistas materializadas proporcionan una instantánea de los datos. Es en el momento de su creación o última actualización. Esto es útil para análisis histórico o informes.
Contras de vistas materializadas
-
Funcionalidad limitada: Después de crear una vista materializada, no puedes cambiar su definición SQL. Tampoco puedes reemplazarla con otra vista del mismo nombre. Las vistas materializadas tampoco pueden consultar tablas externas, comodines o vistas lógicas. Solo admiten un conjunto limitado de funciones SQL. Esto las hace menos flexibles para consultas complejas. Además, no pueden anidarse dentro de otras vistas materializadas, limitando su uso en modelos de datos avanzados.
-
Manipulación de datos directa limitada: No puede actualizar los datos de una vista materializada mediante COPY, EXPORT, LOAD u operaciones DML. Esto reduce la flexibilidad en la gestión de los datos de la vista.
-
Esfuerzo de mantenimiento: Para sincronizar una vista materializada con los datos base, se requieren actualizaciones periódicas. Este proceso de actualización puede generar un alto costo de sistema y consumir recursos. Depende del tamaño del conjunto de datos y la frecuencia de actualización.
-
Actualizaciones frecuentes aumentan la complejidad: Es más difícil mantener las vistas materializadas cuando los datos de origen cambian con frecuencia. Las actualizaciones deben coordinarse cuidadosamente con las tablas base para evitar inconsistencias. Esto agrega complejidad al proceso de gestión.
Por qué deberías tener una base de datos escalable

-
Mejora la colaboración: Una base de datos escalable es un repositorio central y seguro. Permite a todos los miembros del equipo acceder a los datos del proyecto. Mejora la toma de decisiones y simplifica los flujos de trabajo. Lo hace permitiendo un mejor intercambio y colaboración de datos.
-
Soporta múltiples fuentes de datos: Las grandes organizaciones deben integrar datos de múltiples canales. Una base de datos escalable centraliza estas fuentes en un hub unificado, lo que hace más fácil gestionar flujos de información diversos.
-
Gestiona el crecimiento de manera eficiente: A medida que su negocio crece, también lo harán sus datos y las solicitudes de los usuarios. Una base de datos escalable puede ajustarse fácilmente a este crecimiento. Evitará las actualizaciones frecuentes del sistema y mantendrá el negocio en funcionamiento.
-
Maneja picos de tráfico repentinos: Eventos de alto tráfico, como festividades o promociones, pueden aumentar la actividad de los usuarios en los sistemas empresariales. Una base de datos escalable puede aumentar rápidamente su capacidad. Mantendrá el sistema estable durante los picos de tráfico.
-
Mejora el rendimiento: Las bases de datos escalables optimizan el uso de recursos, evitando que el rendimiento se rallice bajo cargas pesadas. Permiten consultas, almacenamiento y procesamiento rápidos de datos. Esto mejora los tiempos de respuesta y mantiene el sistema confiable.
-
Mejora la experiencia del usuario: Una base de datos escalable mantiene su sistema estable. Evita retrasos o caídas, independientemente de cuántos usuarios tenga su empresa. Esto conduce a una experiencia de usuario más fluida y satisfactoria.
Conclusión
Escrito por
Kimmy
Publicado el
15 abr 2026
Compartir artículo
Leer más
Experiencias
Guía del Viajero: Los 10 Mejores Sitios Web de Hoteles para una Planificación Perfecta
25 may 2026
Nuestro último blog
Other
26 may 2026
La lista de verificación completa de desarrollo de eCommerce para dueños de negocios
Experiencias
25 may 2026
Guía del Viajero: Los 10 Mejores Sitios Web de Hoteles para una Planificación Perfecta
Edificio de IA
25 may 2026
Los 10 Mejores Creadores de Portafolios para Diseñadores UX: Muestra tu Trabajo
¡Páginas web en un minuto, impulsadas por Wegic!
Con Wegic, transforma tus necesidades en sitios web impresionantes y funcionales con AI avanzada