Anmelden
Erstellen Sie Ihre Website
Datenbank-Skalierung: Strategien und Best Practices (Aktualisiert 2025)
Um mehr Traffic zu generieren und den Datenfluss zu verbessern, haben wir Strategien und Best Practices zusammengestellt, um Sie bei der Optimierung der Datenbank-Skalierung zu unterstützen. Probieren Sie es jetzt aus.

Befindet sich Ihr Unternehmen in Schwierigkeiten, mit wachsenden Anforderungen Schritt zu halten und zunehmende Daten und Benutzer effektiv zu verwalten? Es könnte Zeit sein, Ihre Datenbank zu skalieren. In diesem Artikel erfahren Sie praktische Schritte, um Ihr überlastetes System zu optimieren und es für zukünftiges Wachstum vorzubereiten.

Was ist Datenbank-Skalierung
Ein Datenbank ist eine organisierte Sammlung von Daten, oft als strukturierte Daten bezeichnet, die auf einem Computersystem gespeichert und abgerufen werden können. Datenbanken sind speziell darauf ausgelegt, Informationen effizient zu verwalten, zu speichern und abzurufen. Ein Datenbank-Management-System (DBMS) kontrolliert normalerweise eine Datenbank. Es vereinfacht den Zugriff, die Verwaltung und die Aktualisierung der Daten in der Datenbank.
Datenbank-Skalierung bedeutet, die Größe und Kapazität einer Datenbank anzupassen. Dies geschieht, um wachsenden Anforderungen wie mehr Daten und Benutzern gerecht zu werden. Sie muss Leistung, Reaktionsfähigkeit und Zuverlässigkeit aufrechterhalten. Ein skalierbares Datenbanksystem sorgt für eine nahtlose Benutzererfahrung, auch wenn das System wächst.
Datenbank-Skalierung: Strategien & Best Practices (Aktualisiert 2025)
Bereit, Ihre Datenbank für Wachstum und Leistung zu optimieren? Ich habe wichtige Strategien und Best Practices zusammengestellt, um Ihnen zu helfen, Ihre Datenbank effektiv zu skalieren.
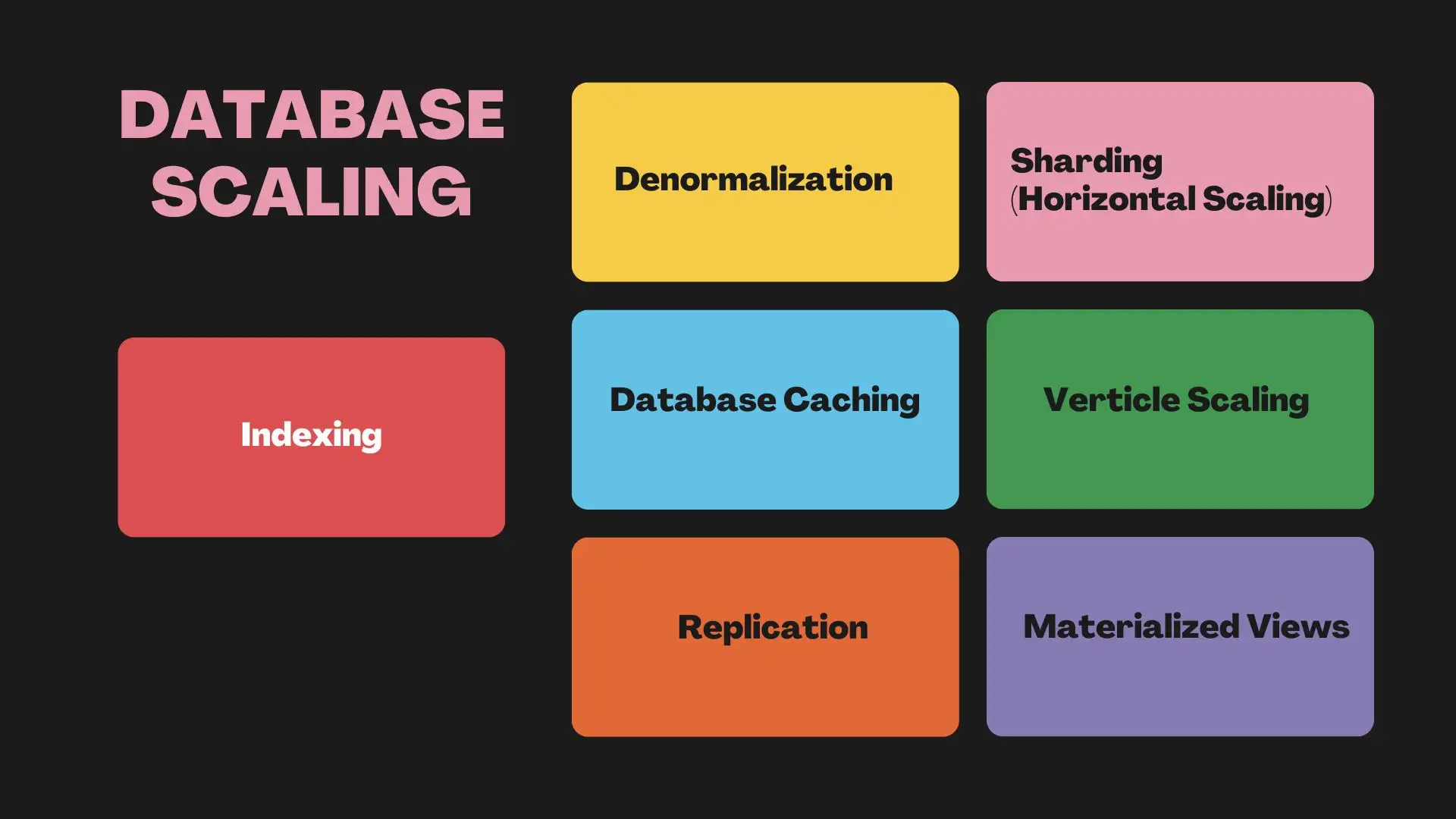
1#Indizierung
Datenbank-Indizierung ist entscheidend für die Datenbank-Skalierung. Sie beschleunigt die Datenabfrage, indem sie schnellere Suchvorgänge ermöglicht. Es ist wie ein Buchindex, der dabei hilft, Themen zu finden, ohne jede Seite zu durchsuchen. Während Indizes die Sucheffizienz verbessern, benötigen sie zusätzlichen Speicherplatz und Schreibvorgänge zur Wartung.
Wichtige Praktiken sind das regelmäßige Analysieren und Optimieren von Abfragen, das Verwenden von Verbindungspools für effiziente Verwaltung, das Partitionieren großer Tabellen und die Auswahl des richtigen Datenbanktyps (SQL vs. NoSQL). Berücksichtigen Sie bei der Gestaltung von Indizes die Indextgröße, die Suche, die Wartung und die Fehlertoleranz. Zusammen tragen diese Faktoren dazu bei, die Gesamteffizienz und Leistung der Datenbank zu verbessern.
2#Denormalisierung
Denormalisierung ist eine der Datenbank-Skalierungs Techniken zur Optimierung. Sie verbessert die Leseleistung, indem redundante Daten zu einem ursprünglich normalisierten Schema hinzugefügt werden. Sie hilft, die Zugriffskosten zu reduzieren, die aufgrund von mehreren Tabellenverknüpfungen in einer normalisierten Datenbank entstehen können, besonders wenn mit großen Tabellen und Indizes gearbeitet wird.
Denormalisierung beschleunigt Abfragen durch Hinzufügen von vorberechneter Redundanz. Allerdings erhöht sie den Speicherbedarf und kann zu Dateninkonsistenzen führen. Häufige Techniken umfassen das Aufteilen von Tabellen und das Hinzufügen abgeleiteter oder redundanter Spalten. Das Verwenden von gespiegelten Tabellen ist ebenfalls üblich. Verwechseln Sie diesen Prozess nicht mit einer Datenbank, die nie normalisiert wurde. Die Denormalisierung erfolgt normalerweise nachdem ein Schema durch Normalisierung optimiert wurde.
Vorteile der Denormalisierung
-
Bessere Skalierbarkeit: Die Denormalisierung kann die Skalierbarkeit von Datenbanksystemen verbessern. Sie erreicht dies, indem sie die Anzahl der Tabellen reduziert und die Leistung verbessert. Die Denormalisierung reduziert die Anzahl der Datenbanktransaktionen beim Lesen von Daten. Diese reduzierte Anzahl von Transaktionen kann sich an unterschiedliche Benutzerlasten anpassen und somit die Skalierbarkeit der Anwendung verbessern.
-
Geringere Komplexität: Die Denormalisierung kann das Datenbankschema vereinfachen. Sie erreicht dies, indem sie Join-Abfragen reduziert und verwandte Daten in weniger Tabellen kombiniert. Ein einfacheres Schema ist leichter zu verstehen, abzufragen und zu verwalten. Darüber hinaus wird diese Einfachheit erheblich Fehler in Bezug auf Datenbankoperationen reduzieren.
-
Bessere Abfrageleistung: Die Denormalisierung steigert die Abfragegeschwindigkeit, indem sie Join-Operationen reduziert. Je nach Anforderung können Abfragen in einer normalisierten Datenbank mehrere Join-Operationen zwischen verschiedenen Tabellen erfordern.
Nachteile der Denormalisierung:
-
Geringere Datenintegrität: Die Denormalisierung führt zu redundanten Daten. Dies erhöht das Risiko von Inkonsistenzen. Updates können möglicherweise nicht korrekt auf allen redundanten Feldern propagiert werden.
-
Höhere Komplexität: Die Denormalisierung kann einige Abfragen vereinfachen. Aber sie kann auch die Datenbank komplizierter gestalten, indem sie doppelte Daten erzeugt. Dies kann zu Diskrepanzen zwischen Datensätzen führen, insbesondere in Szenarien mit gespiegelten Datenbanken.
-
Höherer Speicherbedarf und Kosten: Die Denormalisierung erzeugt redundante Daten. Techniken wie Daten-Duplizierung und Tabellen-Spiegelung beanspruchen Speicherplatz. Dies erhöht die Speicherkosten, was für große Datensätze hoch sein kann.
-
Mehr Updates und geringere Flexibilität: Mit redundanten Daten erhöht sich die Häufigkeit von Updates, was die Datenbankwartung komplizierter macht. Dies reduziert in der Folge die Flexibilität des Systems und macht es schwieriger, sich an veränderte Anforderungen oder Änderungen anzupassen.
3#Datenbank-Caching
Datenbank-Caching ist auch eine Technik für die Datenbank-Skalierung. Es speichert häufig zugewiesene Daten im Speicher. Dies reduziert den Bedarf an wiederholten Datenbankabfragen und Berechnungen. Dieser Ansatz verbessert die Skalierbarkeit und Leistung der Anwendung. Es reduziert die Zeit, die für das Abrufen von Daten aus persistentem Speicher, wie Festplatten oder SSDs, benötigt wird.

Vorteile des Datenbank-Cachings
-
Reduzierter Datenbank-Last: Caching überträgt häufige Abfragen auf die Datenbank. Dies reduziert den Belastung auf Server-Ressourcen. Es ermöglicht es der Datenbank, Anfragen effizienter zu verarbeiten.
-
Leistungsverbesserung: Caching speichert häufig zugewiesene Daten im Speicher. Es reduziert die Antwortzeiten dramatisch und beschleunigt die Datenabfrage.
-
Niedrigere Latenz: Caching-Daten befinden sich in schnellen, in-Memory-Strukturen. Dies minimiert die Latenz und beschleunigt die Antwortzeiten für Benutzer und Apps.
-
Weniger Festplatten-I/O-Operationen: Caching reduziert Festplatten-Lesungen. Es beschleunigt den Datenzugriff und ist effizienter als Festplatten-basierte Speicher.
Nachteile des Datenbank-Cachings
-
Cache-Invalidierung: Es ist schwer zu wissen, wann der Cache aktualisiert werden muss. Aber es ist entscheidend für die Datenkonsistenz.
-
Höhere Kosten für externe Caches: Externe Caching erfordert oft DRAM. Es ist teurer als die Nutzung von SSDs oder HDDs für die Speicherung.
-
Verringerte Verfügbarkeit: Externe Caches haben in der Regel eine geringere Hochverfügbarkeit (HA) als Datenbanken. Dies kann zu Ausfällen führen und die Datenbank bei Cache-Ausfällen belasten.
-
Interferenz mit Datenbank-Cache: Ein externer Cache kann den internen Cache einer Datenbank stören. Dies macht ihn weniger effektiv und erhöht den Festplattenzugriff.
4#Replikation
Jetzt werde ich eine weitere Technik für die Datenbank-Skalierung vorstellen: Replikation. Datenbank-Replikation kopiert die Datenbank und speichert sie in verschiedenen lokalen oder Cloud-Orten. Dies gewährleistet die Datenverfügbarkeit, Fehlertoleranz und Zuverlässigkeit. Es ermöglicht Benutzern, auf dieselben aktuellsten Daten zuzugreifen und verbessert die Systemleistung und Katastrophensicherheit. Die Replikation erfolgt normalerweise in Echtzeit, wenn Daten erstellt, aktualisiert oder gelöscht werden, kann aber auch als einmalige oder geplante Batch-Verarbeitung durchgeführt werden.

Vorteile der Replikation
-
Verbesserte Katastrophensicherheit: Datenreplikation erstellt Datenbank-Kopien an verschiedenen Standorten. Dies gewährleistet eine hohe Verfügbarkeit und Zugriff während Ausfälle durch Katastrophen.
-
Reduzierte Server-Last: Replikation überträgt Daten auf eine replizierte Umgebung. Es reduziert die Last auf die primäre Datenbank. Dies optimiert die Leistung und freisetzt Ressourcen.
-
Verbesserte Datenanalyse: Replikation erstellt isolierte Umgebungen für das Ausführen komplexer Abfragen. Dies ermöglicht Analysten, Daten zu erkunden, ohne die Kernsysteme zu beeinflussen.
-
Echtzeit-Business Intelligence: Replikation ermöglicht den Echtzeit-Zugriff auf Daten über Geschäftsbereiche hinweg. Dies verbessert die Berichtsgenauigkeit und Entscheidungsfindung. Es integriert auch Daten aus verschiedenen Quellen für bessere Business Intelligence.
-
Unterstützung für AI/ML-Apps: Replizierte Datenbanken bieten konsistente, aktuelle Datensätze für das Training von AI/ML-Modellen. Dies verbessert die Vorhersagegenauigkeit und ermöglicht Echtzeit, datenbasierte Apps.
Nachteile der Datenreplikation
-
Risiko der Datenverletzung: Fehler bei der Replikation können Daten beschädigen oder verlieren. Dies stellt ein erhebliches Risiko für die Datenintegrität dar.
-
Erhöhte Kosten: Datenreplikation erfordert die Speicherung und Übertragung mehrerer Datenkopien. Es benötigt viel Speicher und Bandbreite. Dies führt zu höheren Speicher- und Betriebskosten, einschließlich der Notwendigkeit, zusätzliche Mitarbeiter zur Überwachung und Verwaltung des Prozesses einzusetzen.
-
Daten-Sicherheitsrisiken: Die Replikation von Daten, insbesondere zu entfernten Servern, führt zu potenziellen Sicherheitslücken. Sie erschwert auch die Einhaltung von Daten-Schutz- und Privatgesetzen. Unautorisierte Zugriffe und Cyber-Bedrohungen sind jetzt größere Probleme.
5#Sharding (Horizontale Skalierung)
Datenbank-Sharding ist auch eine Möglichkeit, eine Datenbank zu skalieren. Es teilt Daten in Segmente, genannt Shards, und speichert sie auf separaten Servern. Dies verbreitet die Last, was die Leistung und Skalierbarkeit verbessert. Außerdem erhöht Sharding die Fehlertoleranz. Es ermöglicht dem System, weiterzulaufen, auch wenn ein Shard oder Server ausfällt. Dies macht es zu einer widerstandsfähigen Lösung.
Sharding wird oft in Cloud-Anwendungen wie SaaS verwendet. Es ermöglicht mehreren Nutzern, auf große Datensätze zuzugreifen. Es kann auch nach Zeit organisiert werden für Szenarien wie Daten-Eingang von verteilten Geräten. Sharding funktioniert am besten, wenn Transaktionen einen einzelnen Sharding-Schlüssel verwenden. Dies optimiert die Abfrageleistung und minimiert den Kommunikationsaufwand zwischen Shards.

Vorteile von Sharding
-
Verbesserte Leistung: Sharding verteilt Daten auf mehrere Server. Es reduziert die Last jedes Servers und beschleunigt die Abfrage-Antworten.
-
Erweiterte Kapazität: Sharding ermöglicht eine einfache Skalierbarkeit. Wenn die Daten wachsen, können wir Server hinzufügen, um die Kapazität der Datenbank zu erhöhen, ohne die Leistung zu beeinträchtigen.
-
Fehlerisolierung: Wenn ein Shards ausfällt, geht nur ein Teil der Daten verloren. Der Rest des Systems bleibt betriebsfähig. Dies verbessert die Robustheit.
Nachteile von Sharding
-
Sharding ist komplex: Es erfordert sorgfältige Planung. Sie müssen entscheiden, wie die Daten verteilt werden, wie viele Shards erstellt werden und wie Abfragen an den richtigen Shards weitergeleitet werden.
-
Probleme bei der Datenverteilung: Es kann schwierig sein, sicherzustellen, dass die Daten gleichmäßig auf die Shards verteilt sind. Wenn die Daten ungleichmäßig verteilt sind, können einige Shards überlastet werden, was die Leistungsverbesserungen durch Sharding zunichte macht.
-
Komplexe Datenverknüpfung: Das Verknüpfen von Daten über mehrere Shards kann langsam und schwierig sein. Dies kann die Abfrageleistung beeinträchtigen.
6#Vertikale Skalierung
Vertikale Skalierung, auch "Skalierung nach oben," genannt, fügt Ressourcen einem einzelnen Server hinzu, wenn er den Anforderungen nicht mehr gerecht wird. Dies bedeutet, CPU, Speicher oder Speicher hinzuzufügen. Dieser Prozess aktualisiert die vorhandene Server-Hardware, um deren Kapazität zu verbessern.
Vertikale Skalierung ist eine schnelle, einfache Lösung. Dies ist für cloud-basierte Datenbanken richtig. Sie können oft Ressourcen erhöhen, indem Sie die Servereinstellungen anpassen. Es ist ideal, wenn wir die Leistung nur durch Erweiterung der Server-Ressourcen verbessern können. Wir müssen nicht mehrere Server zur Lastverteilung einsetzen.
Vorteile der vertikalen Skalierung
-
Angemessene Aufteilung: Vertikales Sharding teilt eine Tabelle in kleinere, zusammenhängende Teilmengen. Sie können unabhängig verwaltet werden. Dies ermöglicht eine bessere Ressourcennutzung und Leistung in Teilen der Datenbank.
-
Einfach umzusetzen: Vertikale Skalierung ist einfacher als horizontale Skalierung. Sie erfordert keine Änderungen an der Architektur der Anwendung oder die Verwaltung verteilter Systeme.
-
Geringere Netzwerklatenz: Alle Ressourcen befinden sich auf einem einzelnen Server. Dies minimiert die Netzwerklatenz und verbessert die Antwortzeiten.
-
Effiziente Ressourcennutzung: Die Optimierung eines einzelnen Servers maximiert seine Ressourcen. Für einige Workloads ist dies effizienter als die Verwendung mehrerer Server.
Nachteile der vertikalen Skalierung
-
Ungleichgewichtiger Last: Einige Shards können mehr Verkehr erhalten als andere. Dies kann die Systemeffizienz verringern.
-
Verwaltungskomplexität: Die Verwaltung mehrerer Shards macht Aufgaben komplexer. Dazu gehören Wartung, Backups und Synchronisation. Jeder Shard betreibt unabhängig und benötigt mehr Aufsicht.
-
Grenzen der Kapazität: Vertikale Skalierung hat physische Grenzen. Sobald ein Server seine maximale Kapazität erreicht, müssen andere Skalierungsverfahren in Betracht gezogen werden.
-
Komplexe Abfragen: Das Abfragen oder Verknüpfen von Daten über mehrere Shards kann uneffizient und komplex sein und erfordert die Koordination zwischen den Shards.
-
Einzelner Ausfallpunkt: Da alle Operationen von einem einzelnen Server abhängen, kann ein Ausfall dieses Servers dazu führen, dass die gesamte Anwendung heruntergefahren wird.
7#Materialisierte Sichten
In der Informatik ist eine materialisierte Sicht ein Datenbankobjekt. Sie speichert die Ergebnisse einer Abfrage auf Festplatte. Dies statt die Ergebnisse jedes Mal neu zu berechnen, wenn die Abfrage ausgeführt wird. Dieser Prozess zur Erstellung einer materialisierten Sicht wird als Materialisierung bezeichnet. Materialisierte Sichten verbessern die Leistung. Sie ermöglichen die schnelle Abfrage von vorberechneten Daten.

Vorteile materialisierter Sichten
-
Verbesserte Abfrageleistung: Materialisierte Sichten speichern vorberechnete Abfrageergebnisse. Dies verringert die Zeit, die benötigt wird, um komplexe Daten abzurufen. Dies ist besonders vorteilhaft für Abfragen mit großen Datensätzen oder komplexen Berechnungen, wie Aggregationen.
-
Reduzierter Ressourcenverbrauch: Materialisierte Sichten speichern die Ergebnisse von ressourcenintensiven Abfragen. Dies reduziert den Bedarf an wiederholter Abfrageausführung und senkt die CPU-, Speicher- und I/O-Nutzung.
-
Schnellerer Zugriff auf aggregierte Daten: Materialisierte Sichten sind ideal, um die Ergebnisse häufig ausgeführter Aggregationsabfragen zu speichern. Sie ermöglichen einen schnelleren Zugriff auf zusammengefasste Informationen.
-
Entlastung des Workloads: Sie können schwere Berechnungen von Live-Datenabfragen entlasten. Dies verbessert die Datenbankleistung, indem der Workload über die Zeit verteilt wird.
-
Visuelle Daten: Materialisierte Sichten bieten einen Screenshot der Daten. Es ist zum Zeitpunkt ihrer Erstellung oder letzten Aktualisierung. Dies ist nützlich für historische Analyse oder Berichte.
Nachteile von materialisierten Sichten
-
Eingeschränkte Funktionalität: Nach der Erstellung einer materialisierten Sicht können Sie ihre SQL-Definition nicht ändern. Sie können sie auch nicht durch eine andere Sicht mit dem gleichen Namen ersetzen. Materialisierte Sichten können keine externen, Wildcard-Tabellen oder logischen Sichten abfragen. Sie unterstützen nur eine begrenzte Menge an SQL-Funktionen. Dies macht sie weniger flexibel für komplexe Abfragen. Darüber hinaus können sie nicht in anderen materialisierten Sichten geschachtelt werden, was ihre Verwendung in fortgeschrittenen Datenmodellen einschränkt.
-
Eingeschränkte direkte Datenmanipulation: Sie können die Daten einer Materialized View nicht mit COPY, EXPORT, LOAD oder DML-Operationen aktualisieren. Dies reduziert die Flexibilität beim Verwalten der Daten der Ansicht.
-
Wartungsaufwand: Um eine Materialized View mit den Basisdaten synchron zu halten, sind periodische Aktualisierungen erforderlich. Dieser Aktualisierungsprozess kann hohe Systembelastung und Ressourcenverbrauch verursachen. Es hängt von der Datenmenge und der Häufigkeit der Aktualisierungen ab.
-
Häufige Updates erhöhen die Komplexität: Es ist schwieriger, Materialized Views zu verwalten, wenn die Quelldaten häufig geändert werden. Updates müssen sorgfältig mit den Basis-Tabellen abgestimmt werden, um Inkonsistenzen zu vermeiden. Dies erhöht die Komplexität des Verwaltungsprozesses.
Warum Sie eine skalierbare Datenbank benötigen

Skalierbarkeit ist die Fähigkeit eines Systems, sich an veränderte Anforderungen anzupassen. Sie muss wachsende Daten und Nutzer effizient verwalten. Hier sind einige wichtige Gründe, warum eine skalierbare Datenbank für Ihr Unternehmen unverzichtbar ist:
-
Verbesserte Zusammenarbeit: Eine skalierbare Datenbank ist ein zentrales, sicheres Repository. Sie ermöglicht allen Teammitgliedern den Zugriff auf Projektdaten. Sie verbessert die Entscheidungsfindung und vereinfacht Arbeitsabläufe. Dies geschieht durch bessere Datenweitergabe und Zusammenarbeit.
-
Unterstützt mehrere Datenquellen: Große Organisationen müssen Daten aus mehreren Kanälen integrieren. Eine skalierbare Datenbank vereint diese Quellen in einem einheitlichen, zentralen Hub und macht es einfacher, verschiedene Informationsströme zu verwalten.
-
Verarbeitet Wachstum effizient: Wenn sich Ihr Unternehmen ausbreitet, wachsen auch Ihre Daten und Benutzeranfragen. Eine skalierbare Datenbank kann sich leicht diesem Wachstum anpassen. Sie vermeidet häufige Systemüberholungen und hält das Unternehmen im Betrieb.
-
Verwaltet plötzliche Verkehrssteigerungen: Hochverkehrsevents wie Feiertage oder Aktionen können den Benutzeraktivität in Unternehmenssystemen erhöhen. Eine skalierbare Datenbank kann die Kapazität schnell erhöhen. Sie hält das System während des Hochverkehrs stabil.
-
Verbessert die Leistung: Skalierbare Datenbanken optimieren die Ressourcennutzung und verhindern Leistungsverzögerungen bei hoher Belastung. Sie ermöglichen schnelles Datenabfragen, Speichern und Verarbeiten. Dies verbessert die Antwortzeiten und hält das System zuverlässig.
-
Verbessert Benutzererfahrung: Eine skalierbare Datenbank hält Ihr System stabil. Sie vermeidet Verzögerungen oder Ausfälle, egal wie viele Nutzer Ihr Unternehmen hat. Dies führt zu einer glatteren, zufriedenstellenderen Benutzererfahrung.
Fazit
Datenbankskalierung ist entscheidend für effiziente Datenarchivierung und Verbesserung der Software-Systemleistung. Von Indizierung und Denormalisierung bis hin zu Daten-Caching, Replikation, Sharding, vertikaler Skalierung und Materialized Views gibt es eine Vielzahl von Strategien, die je nach Systembedürfnissen ausgewählt werden können.
Jeder Ansatz zur Datenbankskalierung hat seine eigenen einzigartigen Vorteile und Herausforderungen. Im Jahr 2025 ist es entscheidend, die Strategie zu wählen, die am besten zu Ihren Unternehmenszielen und Ihrer Infrastruktur passt.
Geschrieben von
Kimmy
Veröffentlicht am
15. Apr. 2026
Artikel teilen
Mehr lesen
Unser neuester Blog
Webseiten in einer Minute, mit Wegic!
Mit Wegic verwandeln Sie Ihre Anforderungen in beeindruckende, funktionale Websites mit fortschrittlicher KI
Kostenlose Testversion mit Wegic, erstellen Sie Ihre Seite mit einem Klick!
Welche Art von Website möchten Sie erstellen?